Data is the New Solar and Context is the Product
In 2006, Clive Humby famously declared that “data is the new oil.” This cliche has been a useful metaphor for understanding the value, and limitations, of data in technology but it’s time for a new one. Just as the world is moving on from fossil fuels, we too must move on – in the era of generative AI, the most powerful data, contextual user data or edge data, is more akin to solar than it is to oil.
Let me expand. Historically, both oil and data have only been available to those with large-scale infrastructure and specialized equipment. Oil is useful once refined into a usable product like gasoline, and data is most useful when used to train ML models deployed at scale. A small amount of oil or data, does not a company make. Further, even once refined, the byproducts of both, gasoline and ML models respectively, are most powerful when used as specialized tools. It’s much more efficient to power a car with gasoline directly than it is to turn it into electricity to power an electric car. Similarly, an ML model trained on TikTok data is going to be much more useful than a general recommendation system.
While the value of big data isn’t going away, a new type of data, contextual edge data, is becoming more important. Edge data is the personal data generated by a user in the context of using the product. For example, the content they upload and their interactions with the application. When aggregated across many users, this data can become big data, but for that user, it’s just their data. I'll also refer to edge data as contextual data or simply user data.
Solar and edge data share a lot of similar properties. Both solar and edge data are most useful on the edge and even in small amounts. The byproducts, electricity and user data, can be used for many type of work and products. Of course, edge power and edge data are not the solution to all of our problems, we’re still driving gas cars and using big data for recommendation systems. But while oil and big data aren’t going anywhere anytime soon, the balance of importance is shifting towards power and data created, and used, at the edge.
Why has big data been so important?
For the past 10 years, the feedback loop of big data with ML systems has been well understood. Netflix’s data allowed them to compound their advantage by building the best possible movie recommendation system, Google’s search query data allowed them to build the best ranking system, and Zillow’s price data enabled the Zestimate. For traditional ML (numerical prediction) and NLP, big data has been important to train custom models that improve the product. The product then gets more usage, which generates more data, which is used to train better models and the cycle repeats. Data is not just used for training, data is also used at inference as a form of context. Powerful models + user context = personalization.
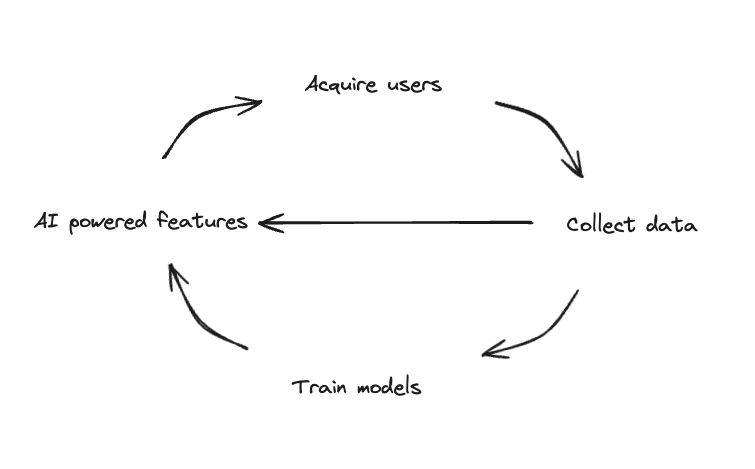
Let’s take a step back and understand how ML models are trained and used. Training high-quality models requires a tremendous amount of data to make accurate predictions in the context of your product. More data = better models.
Let’s take a concrete, albeit simplified, example. YouTube wants to recommend the next video for a user to watch. One of the variables that they might include is the likelihood the user will “like” a video. To train that model, they will feed in billions of data points of user likes as well as supporting features like the previous video, the user’s interests, their subscriptions, and more.
Training requires tons of data. However, to predict whether a specific user likes the video, they just need data on that user. The same features they used to train — subscriptions, previously watched videos, their interests, etc. — will now be fed into the model as parameters. This data, created at the edge, is the context.
The parameters used at both training and inference are hyper-specific to YouTube. This same model would be completely irrelevant when applied to Netflix data because it has no concept of Netflix’s corpus, schema, or underlying user behavior.
The data flippening
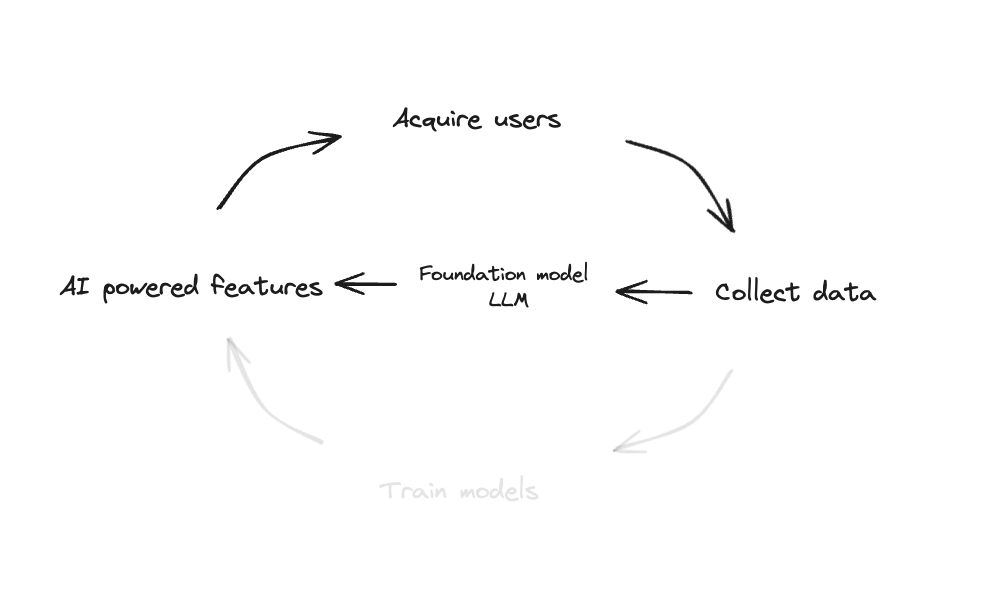
LLMs are a completely different paradigm. They require even more data to train, but now that data is general, not specific to one product. The result is that the models are also able to generalize to many tasks.
Although training data is still important for some companies, it’s no longer the most important thing for most. With the advent of LLMs, edge data used at inference matters significantly more. As Avi Schiffman so presciently put it, context is the product.
Generative AI models are highly generalizable, and capable of utilizing data from various sources, unlike older models that rely heavily on very specific data types. Of course, contextual user data always mattered at inference, but now the set of companies that can use this data has expanded dramatically.
These models excel in cross-domain generalization because they use language as a universal input, a significant shift from previous models that depended on domain-specific features. Future multimodal models will expand this capability by integrating images, videos, and text, enhancing their versatility and application scope.
The net result is that most companies simply don’t need to train models to build AI powered features. They still need data, but this data is valuable only as context data, not also as training data. Of course, techniques like fine-tuning still require data to train models but the amount of data needed is several orders of magnitudes less. A seed-stage startup can fine tune a model whereas in the paradigm of big data ML, only large incumbents could leverage data at scale.
Implications
Over the past decade, it's become a common belief that when startups claim to use AI or ML, it's more about future plans rather than current practices. When we built Stelo (a fraud prevention tool for web3), we envisioned a future ML-powered version capable of detecting transaction fraud. To start, though, heuristics were all we needed or could use.
Now, startups at pre-seed have access to world-class models that generalize to any text or image. The power now lies not in the ability to do machine learning, but rather in gathering context-specific data to enrich prompts and pipelines used at inference.
For example, consider a simple photo-sharing app with an auto caption feature. Five year ago, you might implement basic image classification to identify the main subject and then based on the identified subject, suggest one of ten pre-written captions. This method would use simple machine learning for image classification, allowing the company to claim it as “ML-powered.”
A couple of years and tens of millions of images later, they’d then go and train a machine learning model that would take in previous captions, photos, and trending data and write a compelling caption. They would only be able to do this several years into their journey as a company that's gathered tons of data to train a custom model.
Today, they would simply call GPT-4V and stuff the prompt with the image, the last 10 captions the user has written and some trending captions from that location. In less than 5 seconds they’d have a compelling caption in their user’s voice.
Training data remains crucial, particularly for foundational model companies like Google, OpenAI, and Anthropic. This is especially true in specific domains such as healthcare imaging and legal, where data is vital for training models. However, there has been a significant shift in the balance of importance between training data and edge data. Just like high-capacity batteries impacted the viability of solar at the edge, powerful foundation models are shifting the balance of power away from big data towards edge data.
This shift has two major implications that pull in opposite directions when it comes to disruption. On the one hand, incumbents no longer hold as much of an advantage in developing ML-powered features. Startups can now create equally compelling and personalized experiences using AI. On the other hand, established products with existing distribution can create even more valuable products that are already integrated into users' workflows, making customers less likely to seek alternatives.
The classic question of disruption theory is whether incumbents can innovate faster than startups can reach scale. Impressive but simple demos may have few moats today but their low CAC and instant virality will give them context on their users for tomorrow. And in a world of powerful, democratized models, context is the product.
Thank you to Andy Triedman, Aman Dhesi and Sigalit Perelson for feedback and to Avi Schiffman for inspiring the framing of this post.